Reimagining a User Interface, A Giant Leap
Nearly twenty years ago I had a little brainstorm in the middle of a hard interval session during a ride. As I squinted down at my cycling computer with sweat dripping into my eyes, my heart pounding in my chest, and my lungs gasping for air, I recognized how hard it was to concentrate on the data on the screen while simultaneously keeping a minimal focus on the road ahead. I envisioned an audio interface that spoke data to you at key moments during your workout which would allow you to keep your eyes aimed on the road in front, while keeping your mind trained on the proper effort for the workout.
It only took twenty years for technology to catch up to that vision.

Simultaneously focusing on the road and your data during a maximal effort is challenging
The Apple Watch has a modestly sized screen. The large, 44 mm model, only has a 448x396 pixel display. But, the Apple Watch has a secret super power - it seamlessly pairs with the Apple AirPods, and has a blazing fast CPU capable of performing real-time speech synthesis. The ability of the Apple Watch to perform real-time speech synthesis allows an audio interface to move beyond simply replaying recorded text, and enables the creation of an adaptable audio interface that could play a diverse range of spoken audio queues at key moments during a workout.
Developing the audio based user interface took a giant leap in user interface and experience design.
When most people think of user interface or user experience design, they probably think of graphic user interface (GUI) design, and the visual design and layout of buttons, icons, and text on a device screen. The past few years have seen an explosion of voice user interfaces (VUIs) such as Apple’s Siri or Amazon’s Alexa. Standard voice user interfaces, including Apple’s Siri and Amazon’s Alexa, use a pull based approach where an audio cue from the user triggers the device to listen and then respond to a question or call to action. For example, you trigger Siri to activate with the cue “hey Siri.” You then can ask Siri to perform a task such as “play music” or respond to a question like “what is the weather today?” The request directed at the VUI is called an intent, and the response from the VUI is termed an utterance.

Pull-based Voice User Interface (VUI)
The voice user interface in the World Champ Tech workout apps is distinctly different. It would be hard for a user to pull data from a VUI during a workout when they are out of breath and might struggle to gasp out words, so a workout app VUI instead must push data to the user at appropriate times. A workout app VUI has to use data-based cues and triggers to identify key moments that it should alert a user, and then push out suitable spoken utterances with the information they need to know at that point in the workout.
Identifying these key moments, and creating appropriate data-based cues and triggers is a job for machine learning. Standard definitions of machine learning seem designed to inflate the power of machine learning models while hiding how they actually work. Basically, machine learning models are statistical models of data used to make a prediction based on new input data rather that the traditional use of a statistical model to make inferences about data. With a traditional statistical model, you feed in data, and then get an inference - a conclusion based on data - such as the estimated mean or standard deviation of the data. With a machine learning model, you feed in data, and then make a prediction - a forecast - or classification - identifying a thing according to shared qualities or characteristics - based on a new piece of data. So, a machine learning neural network model trained to identify different types of plants or flowers from an input image, will only make predictions or classifications of those specific plants or flower no matter what the input image. The World Champ Tech machine learning models take health sensor data as input - either heart rate data, energy data, cadence data, velocity data, or global positioning data - and outputs a classification of the users’ current fitness level or classification of the users’ current effort to a specified target effort level.

Workout app push-based Voice User Interface (VUI)
Classification is one way of creating a data trigger or cue. You create a model that classifies data into multiple categories: within a range with acceptable data, and outside the acceptable range where the user should be alerted by a an utterance pushed to the user. For example, a machine learning model could classify heart rate data into an acceptable range for the type of workout the user is engaged in. If the user intends to perform a long endurance workout, the system should notify the user if their heart rate reaches a level indicating that they are exercising near their lactate threshold. Heart rate data above the target range should trigger a warning to the user that their heart rate level is too high, while data below that range the system should alert the user that their heart rate is too low. One challenge with machine learning model classifications is they have a probability associated with the classification. Physical activity sensors are imperfect, and there is always some level of uncertainty associated with each measurement. The art of machine learning model system design is selecting an appropriate trigger threshold value that can effectively distinguish which data is probably inside the target range and which data is probably outside the target range given the measurement uncertainty of the sensors.

A classification machine learning model including high and low trigger thresholds
Designing the utterances that the voice user interface speaks to the user is a critical element in creating a powerful VUI system. Two principles are critical to this design: audio is a conversation and that the system should provide users with information without overwhelming them. Creating utterances the way you speak - and not the way you write - helps to achieve both goals. Utterances consist of both constant text elements and variable text elements. The World Champ Tech voice user interface contains a large set of constant texts set to trigger on different classification types that are combined with small elements of variable texts to create a nearly infinite set of spoken utterances.
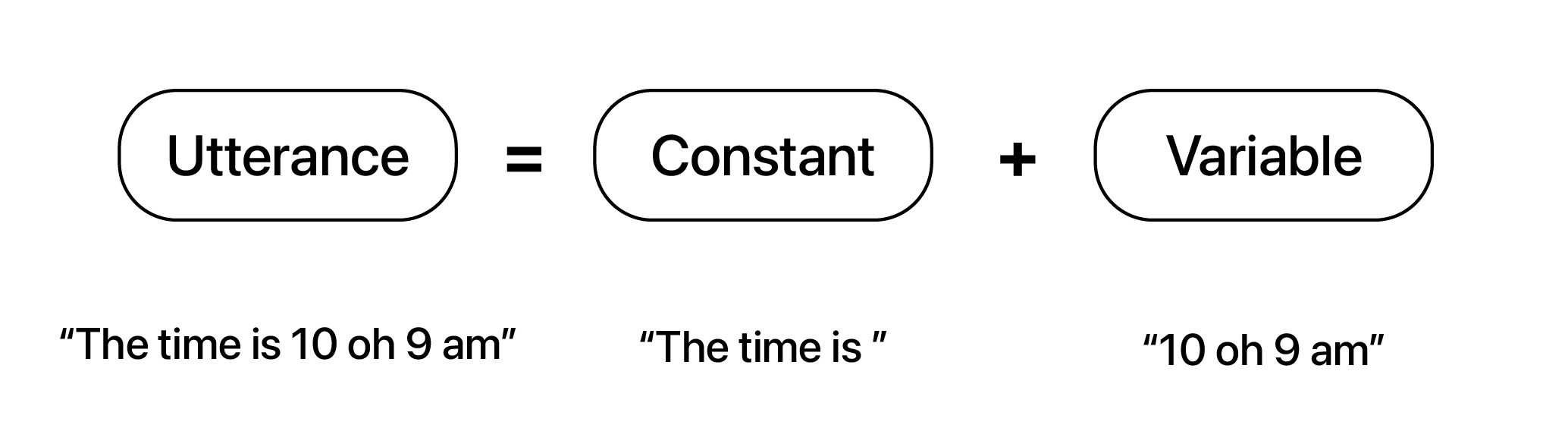
Creation of an utterance containing constant text and variable text
Many workout products advertise new and novel visual interfaces. But, these visual interface improvements are frequently just evolutionary improvements that tweak common design elements. True revolutions in user interface design only occur when entirely new design paradigms are employed to provide information to users in a more convenient formats. World Champ Tech’s novel voice user interface revolutionizes workout app interface design by moving users toward a world where critical workout data is pushed to them at key moments, and allows users to focus better on getting the most out of their workout.